While the exact definition of "Data Scientist" continues to elude us, the job requirements seem to heavily include machine learning skills. They also include a wide range of other skills, ranging from specific languages, frameworks, databases etc, to data cleaning, web scraping, visualizations, mathematical modeling and subject matter expertise. (This breakdown will be the subject of a future post, as I was having some trouble with my web scraper ;))
So for the typical "Data Scientist" role, many organizations want PhD level academic training plus an assortment of nuts and bolt programming or database skills. Most of these job requirements are like a rich and complex mix of "can't find the right candidate" (aka Unicorn). So, as an extension to the Data Science Venn Diagram V2.0, I thought it would be helpful to try to clarify and make some important distinctions regard Machine Learning skills.
Back in the 2002-2003 time frame, I spent a bunch of time trying to code my own Neural Networks. This was a very frustrating experience because bugs in these algorithms can be especially difficult to find and it took time away from what I really wanted to do, which is building applications using machine learning. So I decided back then to use well tested and fully debugged library algorithms over clunky home grown algorithms whenever possible. These days there are so many powerful and well tested ML libraries, why would anyone write one from scratch? The answer is, sometimes a new algorithm is needed.
First, some definitions will help clarify:
- ML Algorithm: A well defined, mathematically based tool for learning from inputs. Typically found in ML libraries. Take the example of sorting algorithms: BubbleSort, HeapSort InsertionSort, etc. As a software developer, you do not want or need to create a new type of sort. You should know which works best for your situation and use it. The same applies to Machine Learning: Random Forests, Support Vector Machines, Logistic Regression, Backprop Neural Networks etc, are all algorithms which are well known, have certain strengths and limitations and are available in many ML libraries and languages. These are a bit more complicated than sorting, so there is more skill required to use them effectively.
- ML Solution: An application which uses one or more ML Algorithms to solve a business problem for an organization (business, government etc).
- ML Researcher/Scientist: PhD's are at the top of the heap. They have been trained to work on leading edge problems in Machine Learning or Robotics etc. These skills are hard won and are will suited for tackling problems with no known solution. When you have a new class of problems which require insight and new mathematics to solve, you need an ML Researcher. When they solve a problem a new ML Algorithm will likely emerge.
- ML Engineer: Is a sharp software engineer with experience in building ML Solutions (or solving Kaggle problems). The ML Engineer's skills are different from the ML Researcher. There is less abstract mathematics and more programming, database and business acumen involved. An ML Engineer analyzes the data available, the organizational objectives and the ML Algorithms known to operate on this type of problem and this type of data. You can't just feed any data into any ML Algorithm and expect a good result. Specialized skills are required in order to create high scoring ML solutions. These include: Data Analysis, Algorithm Selection, Feature Engineering, Cross Validation, appropriate scoring and trouble shooting the solution.
- Data Engineer: A software engineer with platform and language specific skills. The Data Engineer is a vital part of the ML Solution team. This person or group does the heavy lifting when it comes to building data driven systems. The are so many languages, databases, scripting tools, operating systems each with its own set of quirks, secret incantations and performance gotchas. A Data Engineer needs to know a broad set of tools and be effective in getting the data extracted, scraped, cleaned, joined, merged and sliced for input to the ML Solution. Many of the skills needed to manage Big Data, belong in the Data Engineer category.
(Click Image to Enlarge)













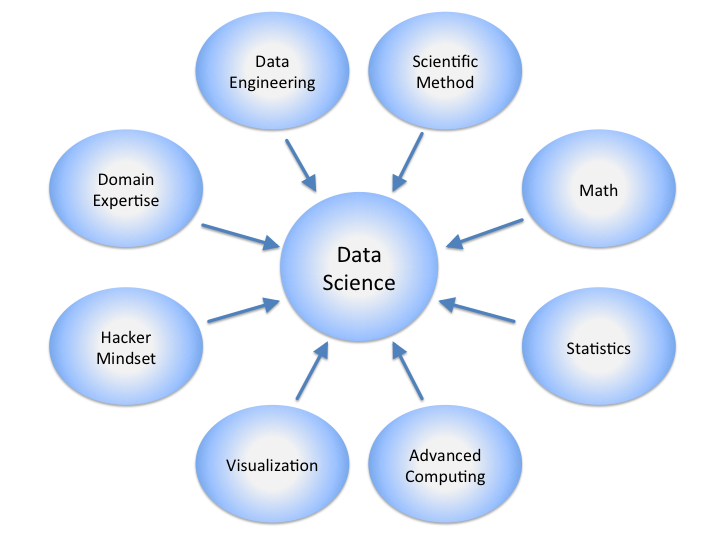{kind=link}